
Traitement de données en table
I- Le fichier CSV
Afficher fichiers CSV
Cacher fichiers CSV
1) Présentation
Les données publiques sont une avancée récente. Il est possible en accédant au site data.gouv.fr d'accéder à différentes données publiques.
Saisir dans la barre de recherche"Opérations coordonnées par les CROSS" : vous aurez accès au récapitulatif de toutes les interventions effectuées par les centres opérationnels de surveillance et de sauvetage du littoral français.
Télécharger le fichier operations.csv
Si vous essayez de l'ouvrir, il est probable qu'un tableur s'ouvre, que ce soit Microsoft Excel ou LibreOffice Calc.
Avec LibreOffice Clac, vous obtiendrez cette fenêtre : En faisant attention à définir la bonne norme d'encodage et le séparateur correct, vous obtiendrez ce tableau : Il est cependant possible d'ouvrir ce fichier avec un simple éditeur de texte, comme Notepad++.
On obtient alors un fichier texte "classique" : On observe cependant que la première ligne est différente des suivantes.
Un fichier CSV est un fichier texte dans lequel la première ligne contient les descripteurs permettant de savoir à quoi correspondent les valeurs associées à chaque item.Télécharger le fichier operations.csv
Si vous essayez de l'ouvrir, il est probable qu'un tableur s'ouvre, que ce soit Microsoft Excel ou LibreOffice Calc.
Avec LibreOffice Clac, vous obtiendrez cette fenêtre : En faisant attention à définir la bonne norme d'encodage et le séparateur correct, vous obtiendrez ce tableau : Il est cependant possible d'ouvrir ce fichier avec un simple éditeur de texte, comme Notepad++.
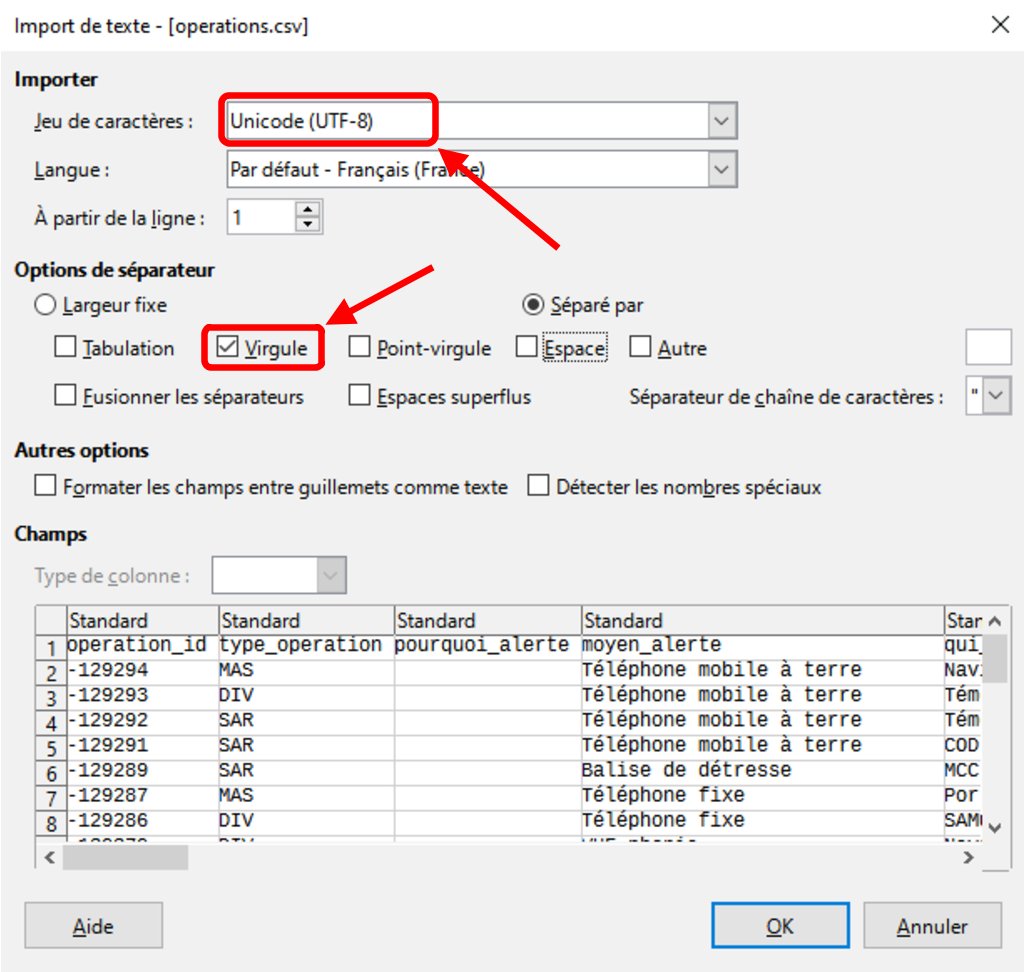
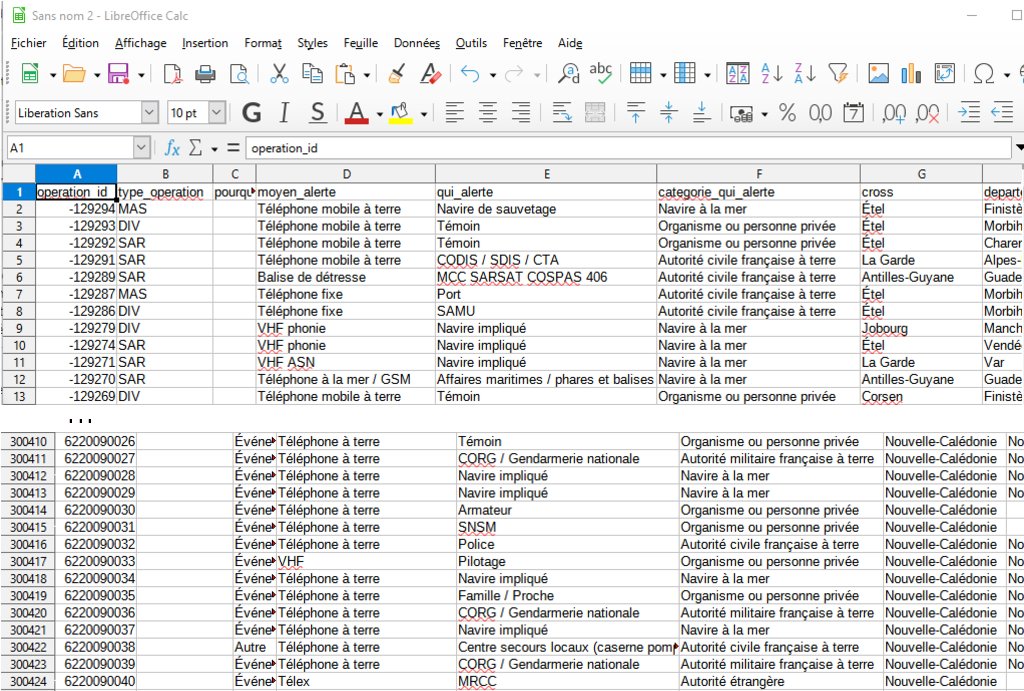
On obtient alors un fichier texte "classique" : On observe cependant que la première ligne est différente des suivantes.

Il est donc nécessaire lors de l'élaboration d'un fichier csv de veiller à ce que les valeurs soient correctement ordonnées.
2) Traitement
L'équivalent en python d'un fichier CSV serait une liste de dictionnaires où:- Chaque élément de la liste correspond à une ligne du fichier csv
- Chaque élément est un dictionnaire ayant pour clés les descripteurs du fichier csv
- Ouvrir le fichier CSV comme un fichier texte
- Extraire chaque ligne et les stocker dans une liste
- Découper chaque ligne à l'aide de la fonction split(",") puisque les données sont séparées par des virgules
- Créer une nouvelle liste, contenant à chaque entrée un dictionnaire dont chaque clé correspondra à chaque descripteur présent dans la première ligne du fichier CSV et chaque valeur correspondra à la valeur indiquée pour la ligne traitée dans le fichier CSV
Affiche code
Cacher code
# -*- coding: utf-8 -*-
def recuperation(chemin_fichier):
sortie=[]
with open(chemin_fichier,"r",encoding="utf-8") as fichier:
for ligne in fichier:
sortie.append(ligne[:-1])
return sortie
def reconstruction(liste):
base=[]
descripteurs=liste[0].split(",")
for ligne in liste[1:]:
entree={}
valeurs=ligne.split(",")
for v in range(len(valeurs)):
entree[descripteurs[v]]=valeurs[v]
base.append(entree)
return base
#récupération d'un fochier csv et réécriture sous la forme d'une liste de dictionnaires
document=reconstruction(recuperation("operations.csv"))
- La fonction recuperation(chemin) va ouvrir le fichier en mode texte et copier chacune de ses lignes dans une liste
- La fonction reconstruction(liste) va créer une liste de dictionnaires en prenant en clés les éléments de la première ligne
- Lors de l'exécution de ce script, le fichier CSV est finalement stocké dans la variable document
On suppose que le script précédent a été exécuté sur le fichier operations.csv, qui se trouve donc maintenant dans la variable document.
- Indiquer la commande à réaliser pour obtenir les informations concernant la première opération du fichier CSV
- Indiquer la commande à saisir pour obtenir les informations concernant la dernière opération du fichier CSV
- Indiquer la commande à saisir pour obtenir la date de l'heure de réception de l'alerte pour l'opération située au rang i.
- Ecrire une fonction recherche(cle,valeur) retournant une liste contenant les informations de toutes les opérations ayant la valeur valeur pour la clé cle
- Ecrire une fonction recherche_max(cle) retournant les informations de l'opération ayant la plus grande valeur pour la clé cle du fichier
3- Le module pandas
Le module pandas permet de traiter simplement un fichier CSV. On arrive ainsi à l'équivalent du scrit précédent par le script suivant :
import pandas
def recuperation2(chemin_fichier):
base=pandas.read_csv(chemin_fichier)
return base
Remarque : chemin_fichier est le chemin d'accès au fichier CSV, qui peut par exemple être fourni par la fonction fichier("ouvrir") du script précédent.
Manipuler des fichiers CSV avec le module pandas
David Roche propose à travers son site Informatique au lycée un très bon tutoriel concernant la manipulation de fichiers CSV avec le mmodule pandas
David Roche propose à travers son site Informatique au lycée un très bon tutoriel concernant la manipulation de fichiers CSV avec le mmodule pandas